DeepSeek-AI has released a preview version of the DeepSeek-V4 series: two Mixture-of-Experts (MoE) language models built around one core challenge making one-million-token context windows practical and affordable at inference time.
The series consists of DeepSeek-V4-Pro, with 1.6T total parameters and 49B activated per token, and DeepSeek-V4-Flash, with 284B total parameters and 13B activated per token. Both models natively support a context length of one million tokens. DeepSeek-V4-Pro was pre-trained on 33T tokens and DeepSeek-V4-Flash on 32T tokens. Model checkpoints for all four variants: DeepSeek-V4-Pro, DeepSeek-V4-Pro-Base, DeepSeek-V4-Flash, and DeepSeek-V4-Flash-Base are publicly available on Hugging Face.
Architectural Challenges of Long Context
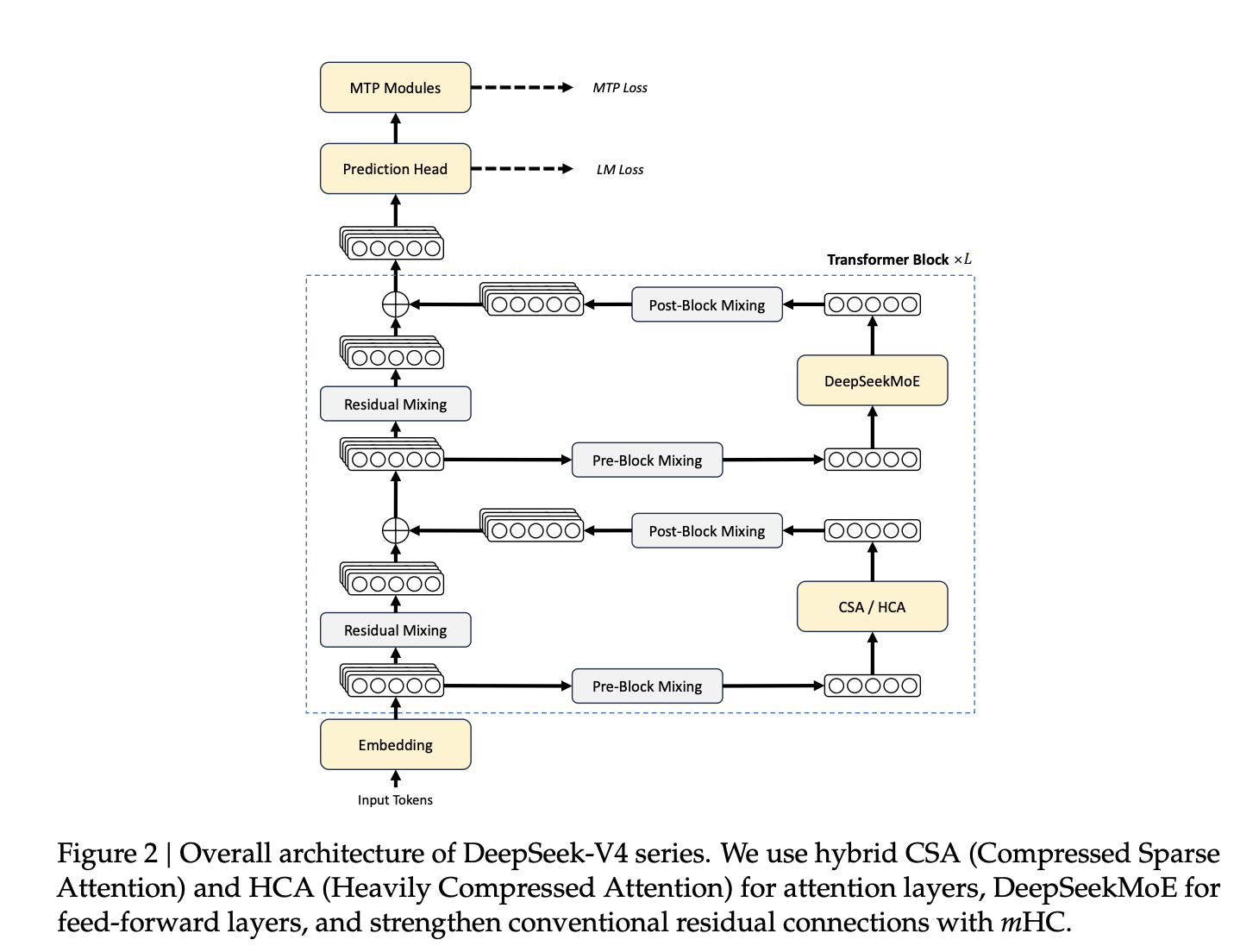
The vanilla attention mechanism in a standard Transformer has quadratic computational complexity with respect to sequence length, doubling the context roughly quadruples attention compute and memory. At one million tokens, this becomes prohibitive without architectural intervention. DeepSeek-V4 addresses this through four coordinated innovations: a hybrid attention architecture, a new residual connection design, a different optimizer, and FP4 quantization-aware training.

Hybrid Attention: CSA and HCA
The central architectural innovation is a hybrid mechanism combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), interleaved across Transformer layers.

CSA compresses the Key-Value (KV) cache of every m tokens into one entry using a learned token-level compressor, then applies DeepSeek Sparse Attention (DSA) where each query token attends only to the top-k selected compressed KV entries. A component called the Lightning Indexer handles sparse selection by scoring queries against compressed KV blocks. Both CSA and HCA include a sliding window attention branch covering the most recent nwin tokens for local dependency modeling.
HCA is more aggressive: it consolidates KV entries of every m′ tokens — where m′ ≫ m into a single compressed entry, then applies dense attention over those representations. No sparse selection step is needed; the compression ratio itself reduces KV cache size.
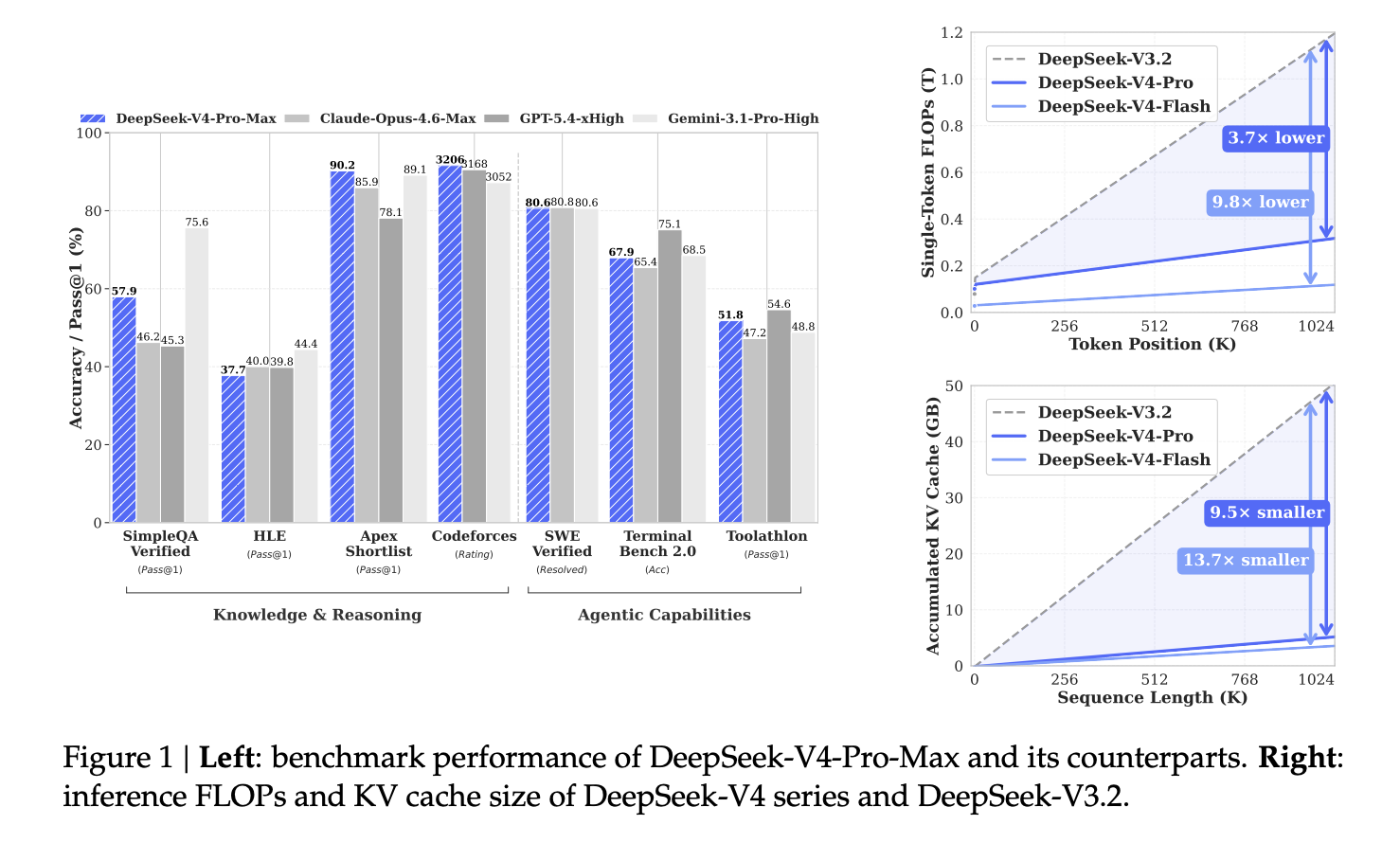
The efficiency gains are substantial. In the one-million-token setting, DeepSeek-V4-Pro requires only 27% of the single-token inference FLOPs (in equivalent FP8 FLOPs) and 10% of the KV cache size of DeepSeek-V3.2. DeepSeek-V4-Flash achieves 10% of single-token FLOPs and 7% of KV cache relative to DeepSeek-V3.2.
Manifold-Constrained Hyper-Connections (mHC)
DeepSeek-V4 replaces conventional residual connections with Manifold-Constrained Hyper-Connections (mHC). Hyper-Connections (HC) generalize residual connections by expanding the residual stream width by a factor of nhc (set to 4 in both models), introducing learned input, residual, and output mapping matrices. Naive HC suffers from numerical instability when stacking many layers.
mHC resolves this by constraining the residual mapping matrix Bl to the Birkhoff polytope — the manifold of doubly stochastic matrices where all rows and columns sum to one and all entries are non-negative. This bounds the spectral norm of the mapping at 1, preventing signal amplification in both the forward pass and backpropagation. The constraint is enforced via the Sinkhorn-Knopp algorithm with t_max = 20 iterations. Mapping parameters are dynamically generated per-input for expressivity.
Muon Optimizer and FP4 QAT
DeepSeek-V4 adopts the Muon optimizer for the majority of its parameters. Muon uses Newton-Schulz iterations to approximately orthogonalize the gradient update matrix before applying it as a weight update. The implementation uses a hybrid two-stage schedule: 8 iterations with coefficients (3.4445, −4.7750, 2.0315) for rapid convergence, then 2 stabilization iterations with coefficients (2, −1.5, 0.5). AdamW is retained for the embedding module, prediction head, static biases and gating factors of mHC modules, and all RMSNorm weights.
For deployment efficiency, FP4 (MXFP4) Quantization-Aware Training (QAT) is applied to MoE expert weights and to the Query-Key (QK) path in the Lightning Indexer of CSA. During inference and RL rollout, real FP4 weights are used directly rather than simulated quantization, reducing memory traffic and sampling latency.
Training Stability at Scale
Training trillion-parameter MoE models introduced notable instabilities. Two techniques proved effective. Anticipatory Routing decouples the backbone and routing network updates: routing indices at step t are computed using historical parameters θt−Δt, breaking the cycle in which routing decisions reinforce outlier values in MoE layers. SwiGLU Clamping constrains the linear component of SwiGLU to [−10, 10] and caps the gate component upper bound at 10, directly suppressing anomalous activations. Both techniques were applied throughout training of both models.
Post-Training: Specialist Experts and On-Policy Distillation
The post-training pipeline replaces the mixed RL stage of DeepSeek-V3.2 with On-Policy Distillation (OPD). Independent domain experts are first trained in mathematics, coding, agent tasks, and instruction following via Supervised Fine-Tuning (SFT) followed by Reinforcement Learning using Group Relative Policy Optimization (GRPO). More than ten teacher models then distill a single unified student model by minimizing the reverse KL divergence between the student and each teacher’s output distribution on the student’s own generated trajectories, using full-vocabulary logit distillation for stable gradient estimates.
The resulting model supports three reasoning effort modes: Non-think (fast, no explicit chain-of-thought), Think High (deliberate reasoning), and Think Max (maximum reasoning effort with a dedicated system prompt and reduced length penalties during RL training).
Benchmark Results
DeepSeek-V4-Pro-Max achieves a Codeforces rating of 3206, ahead of GPT-5.4-xHigh (3168) and Gemini-3.1-Pro-High (3052). On SimpleQA Verified, it scores 57.9 Pass@1, outperforming Claude Opus 4.6 Max (46.2) and GPT-5.4-xHigh (45.3), though trailing Gemini-3.1-Pro-High (75.6). On SWE-Verified, DeepSeek-V4-Pro-Max achieves 80.6% resolved, marginally behind Claude Opus 4.6 Max (80.8%), while Gemini-3.1-Pro-High also scores 80.6%.
On long-context benchmarks, DeepSeek-V4-Pro-Max scores 83.5 MMR on OpenAI MRCR 1M and 62.0 accuracy on CorpusQA 1M, surpassing Gemini-3.1-Pro-High (76.3 and 53.8 respectively), but trailing Claude Opus 4.6 Max (92.9 and 71.7) on both.
Key Takeaways
- Hybrid CSA and HCA attention cuts KV cache to 10% of DeepSeek-V3.2 at 1M tokens.
- Manifold-Constrained Hyper-Connections (mHC) replace residual connections for more stable deep layer training.
- The Muon optimizer replaces AdamW for most parameters, delivering faster convergence and training stability.
- Post-training uses On-Policy Distillation from 10+ domain experts instead of traditional mixed RL.
- DeepSeek-V4-Flash-Base outperforms DeepSeek-V3.2-Base despite having 3x fewer activated parameters.
Check out the Paper and Model Weights. Also, feel free to follow us on Twitter and don’t forget to join our 130k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us